Notes On Caffe Development
Installation
Build Caffe in Windows with Visual Studio 2013 + CUDA 6.5 + OpenCV 2.4.9
[2015-04-01] Build Caffe with Visual Studio 2013 on Windows 7 x64 using Cuda 7.0
OpenCV Installation in Windows
http://docs.opencv.org/doc/tutorials/introduction/windows_install/windows_install.html
HDF5 vs. LMDB
HDF5:
Simple format to read/write.
The HDF5 files are always read entirely into memory, so can’t have any HDF5 files exceed memory capacity. But can easily split data into several HDF5 files though (just put several paths to h5 files in text file). Caffe dev group suggests that divide original large h5 data into small ones so that each h5 data fits < 2 GB.
I/O performance won’t be nearly as good as LMDB.
Other DataLayers do prefetching in a separate thread, HDF5Layer does not.
Can only store float32 and float64 data - no uint8 means image data will be huge.
LMDB:
Uses memory-mapped files, giving much better I/O performance. Works well with large dataset.
Example:
layer {
type: "HDF5Data"
top: "X" # same name as given in create_dataset!
top: "y"
hdf5_data_param {
source: "train_h5_list.txt" # do not give the h5 files directly, but the list.
batch_size: 32
}
include { phase:TRAIN }
}Create LMDB from float data
http://stackoverflow.com/questions/31774953/test-labels-for-regression-caffe-float-not-allowed
https://github.com/BVLC/caffe/issues/1698#issuecomment-70211045
Reference
http://vision.stanford.edu/teaching/cs231n/slides/caffe_tutorial.pdf
https://github.com/BVLC/caffe/issues/1470
“lr_policy” in Caffe
fixed: the learning rate is keped fixed throughout the learning process.
inv: the learning rate is decaying as ~1/T
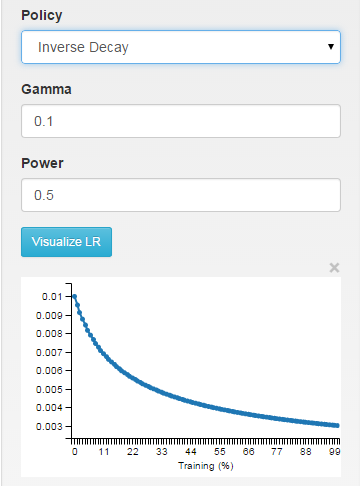
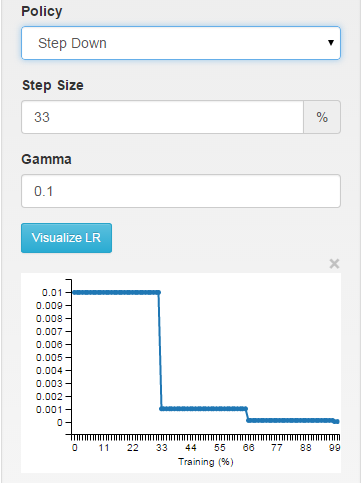
step: the learning rate is piece-wise constant, dropping every X iterations
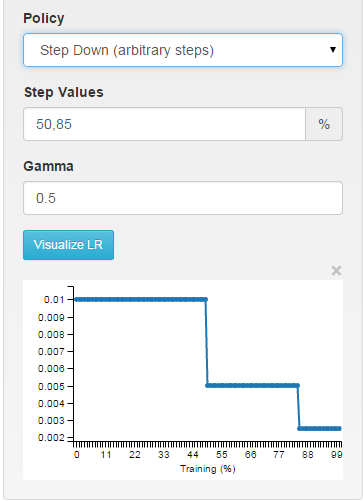
multistep: piece-wise constant at arbitrary intervals
Reference
http://stackoverflow.com/questions/30033096/what-is-lr-policy-in-caffe
Iteration loss vs. Train Net loss
The net output #k result is the output of the net for that particular iteration / batch
while the Iteration T, loss = X output is smoothed across iterations according to the average_loss field.
Reading and Notes
DIY Deep Learning for Vision: A Tutorial With Caffe 报告笔记
Caffe_Manual(by Shicai Yang(@星空下的巫师))
https://github.com/shicai/Caffe_Manual
Why GEMM is at the heart of deep learning
http://petewarden.com/2015/04/20/why-gemm-is-at-the-heart-of-deep-learning/
